

What is a Canonical Tag?
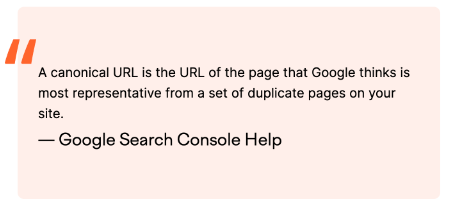
A canonical tag is a way of telling search engines that a specific URL represents the master copy of a page.
We would use this where there are instances of duplicate or near-identical content existing on multiple URLs, that are unable to be resolved through another method such as rewriting content or implementing a redirect.
Essentially, it is a directive that tells search engines which version of a URL you want to appear in search results.
Any content which is classed by search engines as being duplicate or extremely similar can have negative effects on rankings and user experience. Just a few instances of duplicate content can trigger Google to rank your site lower in the search results. You will be unable to recover your rankings until you’ve addressed the duplicate content.
If you don’t tell Google which version of your content should be indexed, then Google will make that choice for you and the duplicate versions will be crawled less often. Sometimes this can lead to the wrong URL being indexed.
Remember – even if you specify a canonical URL, Google may choose a different page as canonical, for various reasons. A canonical tag is a hint not a directive.
Put simply:
A canonical tag can either be self-referencing (where a canonical tag points to a page’s own URL) or can reference another page’s URL to consolidate signals.
Canonical Tags vs 301 Redirect vs Unindex
You should 301 redirect rather than canonicalise the following:
- HTTP to HTTPS
- Non-www to www (or vice versa)
- Non-trailing slash to trailing slash (or vice versa)
- When you delete a page or move it from URL A to URL B
- You move to a new domain name
- If you change your URL structure
Google doesn’t recommend blocking pages via robots.txt or noindexing the content, instead, it is better to let them crawl it and then mark them with a canonical tag:

Valid Reasons for Duplicate Content
There are a few valid reasons why you might have different URLs pointing to the same page:
To support different device types where the site serves different content:
- https://example.com/news/koala-rampage
- https://m.example.com/news/koala-rampage
- https://amp.example.com/news/koala-rampage
To enable dynamic URLs for search parameters, tracking parameters or session IDs:
- https://www.example.com/products?category=dresses&color=green
- https://example.com/dresses/cocktail?gclid=ABCD
- https://www.example.com/dresses/green/greendress.html
If your site saves multiple URLs for the same post or content e.g. Shopify:
- https://www.website.com/products/product-a
- https://www.website.com/featured-collection/products/product-a
- https://www.website.com/sales-collection/products/product-a
All of these can cause duplicate content if they are not canonicalised to the main URL.
Canonical Tag Example
So for example, say you have these 3 duplicate pages:
https://example.com/dresses/green-dresses
https://example.com/dresses?colour=green
https://example.com/dresses/women/green
You would (via Analytics and other methods) determine which is the “strongest” of these 3 pages – this would be your canonical page (not the one with parameters!)
You need to mark the all 3 pages with the same rel=”canonical” link tag, like this:
<link rel=”canonical” href=”https://example.com/dresses/green-dresses” />
This points Google to the strong version of the content and tells it that it should only index that one.
So in this case, the strongest page has a self-canonical tag and the other two URLs are canonicalised to the main one:
https://example.com/dresses/green-dresses has a self-canonical of https://example.com/dresses/green-dresses
https://example.com/dresses?colour=green is canonicalised to https://example.com/dresses/green-dresses
https://example.com/dresses/women/green is canonicalised to https://example.com/dresses/green-dresses
This means that https://example.com/dresses/green-dresses should be indexed by Google.
How to Implement Canonical Tags
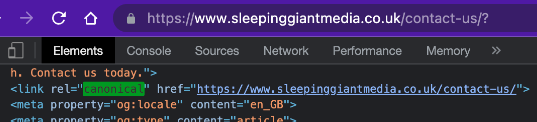
There are 2 main ways to implement canonical tags, the most common of which is to use a meta tag in the <head> part of the page.
rel=canonical <link> tag
Add a <link> tag in the code for all duplicate pages, pointing to the canonical page.
Pros:
- Can map an infinite number of duplicate pages.
Cons:
- Can be complex to maintain the mapping on larger sites, or sites where the URLs change often.
- Only works for HTML pages, not for files such as PDF. In such cases, you can use the rel=canonical HTTP header.
The tag looks like this: <link rel=”canonical” href=”URL OF PAGE”>
Canonical tags only go in the <head> part of the page, it cannot go in the <body> or anywhere else.
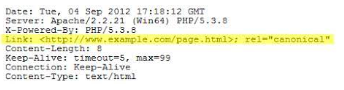
Canonical HTTP header
If you have access to your server and configure it, you can send a rel=canonical header in your page response rather than a HTML tag. This is especially useful for non-HTML documents such as PDF files.
Pros:
- Can map an infinite number of duplicate pages.
Cons:
- Can be complex to maintain the mapping on larger sites, or sites where the URLs change often.
Using PHP
Adding this header() function before any HTML is output will append a link rel=”canonical” HTTP header to the headers before they get sent.

Using .htaccess
The HTTP Header can be modified relatively easily using .htaccess for all content-types, such as PDF files. This solution works well for sites that have a relatively small amount of files which you need the header added to.

Simply replace file.pdf with the name of your pdf file and then page.html with the canonical URL for the PDF like this:
<Files “file-to-canonicalize.pdf”>
Header add Link “< http://www.website.com/canonical-page/>; rel=\”canonical\””
</Files>
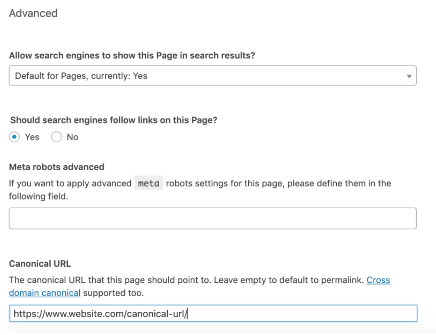
Yoast SEO (WordPress) & Canonical Tags
You can add canonical tags to WordPress sites on individual pages by navigating to the Advanced section of the Yoast SEO section of a page (at the bottom) and adding a canonical tag there. This is only really suitable for individual pages, as it is very time-consuming to implement on larger sites page by page.
Shopify & Canonical Tags
You can “fix” the canonical tags on Shopify by editing the theme’s liquid files. Shopify typically shows a single products on the following URLs:
- https://www.website.com/products/product-a
- https://www.website.com/featured-collection/products/product-a
- https://www.website.com/sales-collection/products/product-a
They all return the same product, just on different URLs, and although Shopify does automatically canonicalise URLs, you will find internal links pointing to the duplicate versions, which can be confusing for search engines. You can clean this up by editing the theme’s collection-template.liquid file. Search for {{ product.url | within: collection }} in the file:

Edit this to say {{ product.url }}
You should now find that both your canonical tags and internal links are correct.
Blogs & Paginated Pages and Canonical Tags
Paginated pages such as news and blog pages need to be specially considered. You should not canonicalise to the first page of a series, otherwise Google won’t necessarily see the other content.
Each news / blog paginated page should have a self-canonical tag, e.g. page 2 should have this:
<link rel=”canonical” href=” https://www.domain.com/category?page=2″/>
Here’s how your canonical tags should look:
Root paginated page (the first page in your paginated series)
<link rel=”canonical” href=”https://www.domain.com/category“/>
Second page in the series (first after the root)
<link rel=”canonical” href=” https://www.domain.com/category?page=2″/>
Try to ensure that each paginated page is unique and valuable by adding relevant text to those pages.
Note: If you have a “view all” version, then it is ok for all pages within a series to be canonicalised to the view all page.
Parameter Pages & Canonical Tags
If you have pages with parameters on your site, this can lead to extensive duplicate content. Some examples may be from site searches, product filter options or tracking parameters, e.g:
- https://www.domain.com/?utm_source=newsletter&utm_medium=email
- https://www.domain.com/collections/women?pf_t_colour=Pink&pf_t_outsole=Light+Duty
- https://www.domain.com/search/?tag=rainbows
You can add a self-canonical tag to the main page, which will help to avoid parameter pages being indexed in search results.
So the canonical tag for https://www.domain.com/?utm_source=newsletter&utm_medium=email would be <link rel=”canonical” href=”https://www.domain.com/”>
The canonical tag for https://www.domain.com/collections/women?pf_t_colour=Pink&pf_t_outsole=Light+Duty would be <link rel=”canonical” href=”https://www.domain.com/collections/women“>
The canonical tag for https://www.domain.com/search/?tag=rainbows would be <link rel=”canonical” href=”https://www.domain.com/search/“>
Canonicals and Languages
It is a common misconception that languages are not considered duplicates. If the main content is in the same language (e.g. the header, footer and other text) is translated, but the body remains the same, then these are considered duplicates.
For example, if you have a site which has different pages for English speaking users in the UK, USA and Ireland, these pages will be considered duplicates.
To avoid this, you need to use hreflang tags along with canonical tags to help search engines work out which version of a page is for which language.
- Always specify a canonical tag in the same language. If you can’t use the best possible substitute language.
- Make sure you specify self-canonicals too.
Syndicated Content & Canonical Tags
This is where your content is used on other peoples websites, for example news posting or blog posts which appear on multiple sites which you are the author of.
You can reach out to the sites which have your post or news article on and ask them to add a rel=canonical tag pointing back to your post on their page.
Your site then is recognised as the original publisher and any links to the article on other people’s sites will help you too!
Canonical Tag Best Practices
- If you are canonicalising a page to another page, make sure it’s an indexable page! Also, make sure it’s not blocked by robots.txt!
- Don’t canonicalise to a redirected page or a 404 page
- Only canonicalise pages which are a duplicate or are near-identical.
- Keep internal linking consistent – only link to the canonical URL, not the duplicate ones
- Use absolute URLs not relative ones e.g. https://www.mysite.com/page-one rather than /page-one
- Only specify one canonical tag per page
- Specify the correct domain protocol e.g. http or https, either trailing slash or non-trailing slash and non-www or www URLs
- Use Self-Referencing Canonical URLs if you are not canonicalising that page to a different URL. This helps prevent spammy scraper sites from taking credit for your content if you add a self-referential rel=canonical link on your site’s pages.
- Don’t chain canonical tags (e.g. A -> B, B -> C).
- Don’t use the URL removal tool for canonicalization. It removes all versions of a URL from Search.
- Don’t specify different URLs as canonical for the same page using the same or different canonicalization techniques (for example, don’t specify one URL in a sitemap but a different URL for that same page using rel=”canonical”).
Interested in learning more, or having someone do this stuff for you? Get in touch, or check out our free SEO audits.
Article originally posted by Sleeping Giant Media.



